Links table
Abstract and 1 introduction
2 before training
2.1 Distinguished symbol
2.2 Pre -training data
2.3 Stability
2.4 Inference
3 alignment data and 3.1 data
3.2 Refining strategy
4 Human reviews and safety test, and 4.1 Claims for evaluation
4.2 basic lines and evaluation
4.3 Inter-Anotator Agreement
4.4 Safety test
4.5 Discussion
5 measurements measuring and 5.1 text
5.2 Images to text
6 related work
7 Conclusion, Decisions, shareholders and references
Excessive
A. Samples
for. Additional information on human assessments
5.2 Images to text
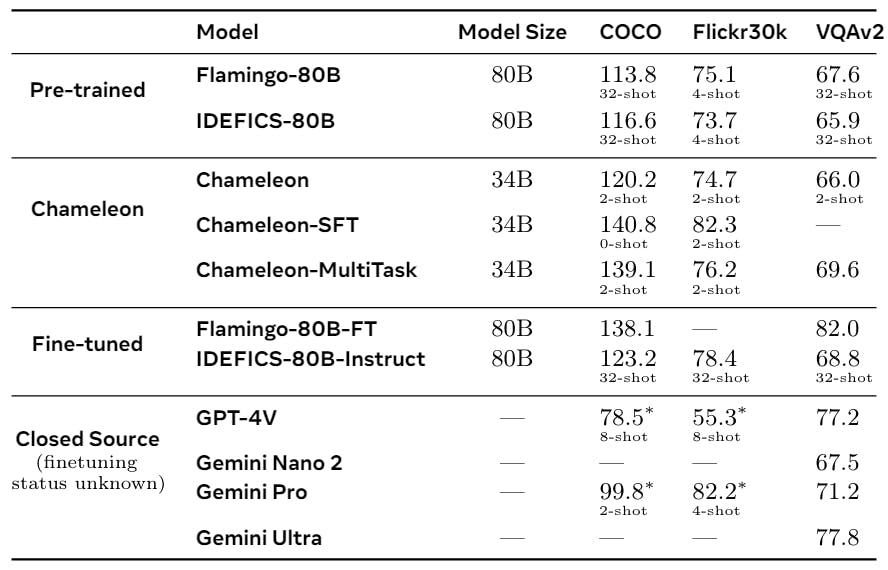
Then we evaluate the chameleon on the task segment that requires a conditional text generation in an image, specifically on the labels of the illustrations of the images and the tasks of re-visible questions, and the current results of the 34b nature in Table 7. With our previously trained model, we also offer specially modified results on all tasks together (CHEMENON 34B-Multask). (CHAMELEON-34B-SFT).
We evaluate models available for late late source: specifically Flamingo 80b (alayrac et al., 2022), Idefics 80b (laurençon et al et al. We note that we have not taken any special care when coordinating pre -training data to ensure that 0 shots can be done effectively. Therefore, we increase the input images or questions with the published claims used by other models. This was intentionally done to maintain the sincerity of pre -training data.
• An explanatory designation of the image: As for the evaluation assessments of the photos, we report the results of the apple juice (Vedantam et al (Chen et al., 2020). For chameleon models, we restrict the illustrations of 30 symbols. We evaluated the GPT-4V and Gemini models using many claims and generation lengths through their application programming facades and reporting the best performance we could achieve.
In the pre-trained open category, CHELEONON-34B (2-shot) excel over the largest 80b models of Flamingo and Idefics on COCO with 32 shots, with their performance on Flickr30K. Regarding the seized models/closed source, both multi-task and SFT variables outperform Chamleon-34b on all other models on COCO, while the SFT model exceeds other models with a multi-task model is a close competitor.
• Answer visual questions: As for the answer to the visual questions (VQA), we report the performance of the Testdev division of VQA-V2 (GOYAL ET AL., 2017). For VQA-V2, the CHAMELEON-34B model that was previously trained with 2 shots with 32 performances of Flamingo and Enter models, while for closed/closed models, intimate models-34 B-Multass, GTT-4, GTT-4, GTT-FTS- Gemini Ultra. LLAVA-1.5 surpasses Charmeleon-34b on VQAV2 is likely to be due to its additional refinement on


GPT-4 conversations, ShareGPT (ShareGPT, 2023), GQA (Hudson and Manning, 2019), and VQA data groups at the region level, but they are dramatically backward in other tasks.
In general, we find that Chameleon is somewhat capable of competing for both the labels of the explanatory name and the tasks of VQA. They compete with other models using much lower training examples in context and with the sizes of smaller models, in both the pre -trained evaluations.
author:
(1) The chameleon team, exhibition in Meta.



 may appear 52 % correction; Mutuum Finance (MUTM) expects to rise to $ 4")
