Links table
Abstract and 1 introduction
2 related work
3 roads and 3.1 models
3.2 Data sets
3.3 Evaluation measures
4 results and 4.1 increase the number of examples of showing
4.2 Air Information Impact
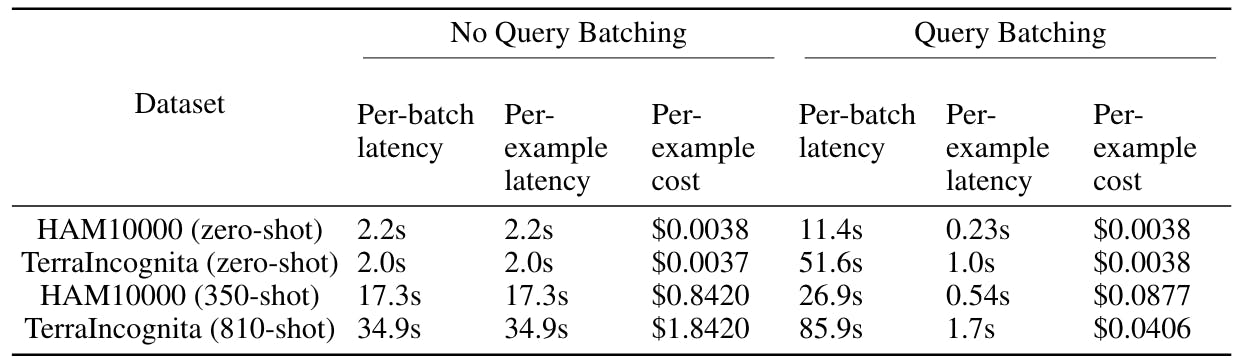
4.3 cost and cumin analysis
5 discussion
6 conclusion and references
A. The claims used for ICL experiments
Immediate selection
C. GPT4 (V) -Turbo Performance under many ICL
D. Many ICL performance in medical quality guarantee tasks
Thanks, appreciation and revelation of funding
5 discussion
In this study, we evaluate many identical models on the latest models across 10 data sets and we find fixed performance improvements across most data sets. Renewable information with many international shots ICL display more to a large reduction in cumin costs and inference costs without compromising the performance.
The results we have reached indicate that these multimedia basic models have an ICL ability with large numbers of examples that appear, which may have significant effects on their practical use. For example, it was previously impossible to adapt these large and private models with


New tasks and fields, but many ICL shots will enable users to take advantage of examples of models adaptation. One of the important features of many ICL is its ability to obtain quick results even on the same day of the form of the form, which is why we can end our evaluation using GPT-4O within days. Moreover, the models that make the open source are the usual practice when practitioners have access to moderate -sized data collections, but many ICL may remove the need to install, making it easier to develop custom methods. We note that it remains to see how the traditional control of these models is compared to many international shots with basic models in terms of absolute performance and data efficiency, so future work must explore this. In addition, it is important to study general issues that affect these basic models, such as hallucinations and biases, in light of the context of many ICL and air quarrels. For example, it will be interesting to explore whether they are carefully sponsored and careful similar groups can reduce biases across different sub -groups. We leave this for future work.
Our study has restrictions. First, we only explore the performance under many ICL in photo classification tasks and with special foundation models. We believe that these are the most practically relevant multimedia settings, but it is useful for future work to explore the potential benefits from many international shots in other tasks and with the next multi-source basic models like Llama-3 [30]. Second, even after the recent developments to increase the size of the context, the volume is prohibited to use many international shots from data groups with a large number (several hundred or more) of the categories. We expect the sizes of context windows to continue to increase in size over time, which will reduce this problem. Third, the data sets used to train these special models have not been detected, so it is difficult to know if the models have been trained in the data sets that we have chosen. We confirm that the zero performance through data groups is far from perfection, which provides evidence that data groups have not been used for training, but we cannot determine this with certainty.
6 Conclusion
In short, it appears that multimedia basic models are capable of many international shots. We believe that these results pave a promising path forward to improve the ability to adapt and access to large multimedia basic models.
Reference
[1] Tom B Brown, Benjamin Man, Nick Ryder, Melanie Sobbah, Jared Kaplan, Privulala Darioal, Arvind Nylacantan, Branaf Sheam, Geresh Sastir, Amanda Askil, Sanhini Agharwal, Ariel Herbert, Grechen Krgeger Ziegler, Geoffry Woo, Clemens Winter, Christopher Hess, Mark Chen, Erik Sigller, Missus Litoin, Scott Gray, Benjamin Chase, Jacques Clark, Christopher Berner, Sam Mogansh, Alec Radford, Elia Sutskver, and Daro Ameudi. Language models are few learners, 2020.
[2] Archive Paramey and Mino Lee. Learning from a few examples: a summary of methods to learn a little. Arxiv Preprint Arxiv: 2203.04291, 2022.
[3] Yaqing Wang, Quanming Yao, James T Kwok, and Lionel M Ni. Circular from some examples: a survey about learning a little shot. ACM (CSUR), 53 (3): 1-34, 2020.
[4] Josh Hisham, Stephen Adler, Sandyini Agarawal, Lama Ahmed, Elig Akaya, Florence Lioni Aleman, Dyouja Al -Mida, Janko Altshmatt, Sam Al -Tamman, Shiamal Anvesat, and others. GPT-4 Technical Report. Arxiv Preprint Arxiv: 2303.08774, 2023.
[5] Zhongyi Han, Guanglin Zhou, Rundong He, Jindong Wang, Xing XIE, Tailin Wu, Yilong Yin, Salman Khan, Lina Yao, Tongliang Liu, et al. How good is adapting to GPT-4V (ISION) with distribution attacks? Primary investigation. Arxiv Preprint Arxiv: 2312.07424, 2023.
[6] Xingxuan Zhang, Jiansheng Li, Wenjing Chu, Junjia Hai, Renzhe Xu, Yuqing Yang, Shikai Guan, Jiazheng Xu, and Peng Cui. On the circular outside the distribution of large multimedia models. Arxiv Preprint Arxiv: 2402.06599, 2024.
[7] Mukai Li, Shansan Gong, Jiangtao Feng, Yiheng Xu, Jun Zhang, Zhiyong Wu, and Lingpeng Kong. Frequently learning with many examples of illustration. Arxiv Preprint Arxiv: 2302.04931, 2023.
[8] Rishb Agarawal, Avi Singh, LeeM Chang, Pernd Pont, Stephanie Chan, Ankish Anand, Zuhair Abbas, Azad Nova, John de Coyes, Eric Chu, and others. Many learning in the context. Arxiv Preprint Arxiv: 2404.11018, 2024.
[9] Amanda Berch, Five Ji, Uri Alon, Jonathan Pirante, Matthew R Gormeli, and Graham Newbig. Learning within the context with long context models: in -depth exploration. Arxiv Preprint Arxiv: 2405.00200, 2024.
[10] Hoochhe Zhao, ZeFan Cai, Shuzheng Si, Xiaojian MA, Kaikai An, Liang Chen, Zixuan Liu, Sheng Wang, Wenjuan Han, and Baobao Chang. MMICL: Enable vision language model with multimedia learning in context. Arxiv Preprint Arxiv: 2309.07915, 2023.
[11] Zhoujun Cheng, Jungo Kasai and Tao Yu. Payment of payments: effective inference with large language language modeling interfaces. Arxiv Preprint Arxiv: 2301.08721, 2023.
[12] Jianzhe Lin, MAURICE Diesendruck, Liang Du and Robin Abraham. Batchprompt: Complete more. Arxiv Preprint Arxiv: 2309.00384, 2023.
[13] Gia -Leo, Tinghan Yang, and Jennifer Neville. Cliqueparcel: LLM is calling for a participation in improving efficiency and sincerity. Arxiv Preprint Arxiv: 2402.14833, 2024.
[14] Guijin Son, Sangwon Baek, Sangdae Nam, Ilgyun Jeong, and Seungone Kim. Multi -task inference: Can large language models follow multiple instructions simultaneously? Arxiv Preprint Arxiv: 2402.11597, 2024.
[15] Siyu Xu, Yunke Wang, Daochang Liu, and Chang Xu. Claim to attach: visible budget visual recognition with GPT-4V. Arxiv Preprint Arxiv: 2403.11468, 2024.
[16] Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lllencrap, Jeanbapette Alyraac, Radu Soricut, Angeliki Lazaridou, Orhan Africa, Julian Schrittwieser, et al. Gemini 1.5: Opening a multimedia understanding through millions of symbols from context. Arxiv Preprint Arxiv: 2403.05530, 2024.
[17] Yixuan Wu, Yizhou Wang, Shixiang Tang, Wenhao Wu, Tong He, Wanli Ouyang, Jian Wu, and Philip Torr. Dettoolchain: a new model calling for the launch of the MLLM detection capacity. Arxiv Preprint Arxiv: 2403.12488, 2024.
[18] Johang Zang, Wei Lee, John Han, Kayang Chu, and changing Chen Louis. Detection of contextual organisms with large multimedia language models. Arxiv Preprint Arxiv: 2305.18279, 2023.
[19] Philip Tachandel, Cliff Rosindal, and Harrad Kitler. The ham10000 data collection, which is a large collection of multiple endoscopic images for common pigmented leather pests. Scientific data, 5 (1): 1-9, 2018.
[20] Kai Jin, Xingru Huang, Jingxing Zhou, Yunxiang Li, Yan Yan, Yibao Sun, Qianni Zhang, Yaqi Wang, and Juan Yee. FIVES: Fundus Data Data collection for the intelligence -based artificial vessel. Scientific data, 9 (1): 475, 2022.
[21] Jeremy Erfin, Branaf Rajburkar, Michael Ko, Yivan Yu, Silviana Siuria Ilkos, Chris Chot, Henrik Marklong, Bahzad Hagu, Robin Paul, Katie Shabanskaya, and others. Chexpert: A large chest radiology collection with uncertainty stickers and comparing experts. In the facts of the AAAI AI Intelligence Conference, Volume 33, Pages 590-597, 2019.
[22] Peter Pande, Oscar Jessenk, Kirin Manson, Markuri van Dyck, Macrenka Balnankol, Mick Hermesen, Papak Ichhami Bayndardi, Pyongja Lee, Kyungi Bang, Oksia Chong, and others. From the discovery of individual metastasis to classification of the condition of the lymph node at the patient level: the challenge of the Camelyon17. IEEE transactions on medical photography, 38 (2): 550-560, 2018.
[23] Sarah Perry, Grant Van Horn, and Peter Peruna. Acknowledging Terra hidden. In the facts of the European Conference on Computer Vision (ECCV), pages 456-473, 2018.
[24] Yi Yang and Shawn New Nassam. The optical floor bag and spatial accessories to classify land use. In the facts of the eighteenth international conference on the progress of geographic information systems, pages 270-279, 2010.
[25] Patrick Hilber, Benjamin Bishki, Andreas Dajr, and Damian Port. Eurosat: A new data collection, the standard of deep learning standard for land use and ground cover classification. IEEE Journal for topics selected in the Earth’s Applied Earth notes and remote sensing, 12 (7): 2217-226, 2019.
[26] Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In 2012, IEEE Conference on Computer Vision and Patterns Learn, Pages 3498-3505. IEEE, 2012.
[27] Mircea Cimpoi, Subhransu Maji, iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Description of textures in the wild. In the facts of the IEEE conference on computer vision and identification of patterns, pages 3606-3613, 2014.
[28] Yuanfeng Ji, Lu Zhang, Jiaxiang Wu, Bingzhe Wu, Long-Kai Huang, Tingyang Xu, Yu Rong, Lanqing Li, Jie Ren, Ding Xue, et al. DROGOOD: OPod Data Coordinator (OOD) and a criterion for drug detection with the help of AI-focusing on prediction problems with the explanatory comments of noise. Arxiv Preprint Arxiv: 2201.09637, 2022.
[29] Wei-Lin Chen, Cheng-Kuang Wu and Hsin-Hsi Chen. ECL: Zero learning in the context with self -created demonstrations. Arxiv Preprint Arxiv: 2305.15035, 2023.
[30] Meta Llama 3: LLM is the most open publicly available. Url https: //ai.meta.com/blog/Meta-lamada-3/.
 cools and heats gold, but this distinctive code of $ 0.025 may save the best in the upward trend now")



 Lags: Struggling to reignite bullish momentum")