
The perfect size for Kubernetes groups is a question today 0 and requires a specific answer.
You find one giant group on a tip of the spectrum and many of the small size on the other side, with each group between them. This decision will affect your organization for years to come. Worse than that, if you decide to change your topology, you are on a time and expensive journey.
I want to include the pros and cons of every approach in this post. After that, I will settle the discussion once and forever and argue that choosing the giant mass option is better.
A single giant mass approach
Making a decision on one giant has great benefits.
Better use of resources
Kubernetes is designed to deal with publishing operations on a large scale, initially focusing on managing thousands of nodes to support wide and complex barefoot applications. This expansion is a major advantage of its beginning, which enabled it to organize resources across the widely distributed systems.
Thus, the Kubernetes group is scheduling in essence: it knows how to run the burdens of work on the contract according to the restrictions. Without restrictions, you will be happy with the work of work burdens through the available contract. If you divide the group into multiple groups, you lose this benefit. You can have positions in which one group is in lethargy while there is another group close to hunger resources and must eliminate work burdens and kill pods.
Low operational general expenses
Good kubernetes practices are generated to make a backup copy of your ETCD data, monitor your mass standards, record your group events, provide security -related tools, etc. Size, it makes sense to be more effective of time to operate groups.
For example, with regard to the standards, you have prepared one printheus, which is likely to be assembled to deal with additional traffic, and do it. It can reduce automation from the frequent side to install and maintain an equal to each group, but you still eventually with many cases that have groups (or more). Prometheus is just one example because many group managers have a long list of tools they run in each group.
Direct communication and service contact
Communications to the service within one clear and direct group. It indicates
You will need a tool to help you communicate between the mass, from the simplicity of the external DNS with loadbalancer to the complexity of a complete solution like Istio-each of the ends of the spectrum delegation time and operating costs.
Simplified governance
Since each part of the same group is within one group, one can implement a central set of policies with a uniform approach. For example, you can create a name space for each team and environment, and restrict access to members of this team only.
Once you start to have multiple groups, even if you follow the same approach, the rules of politics will be repeated through groups, with possible differences that will be injured over time.
Cost efficiency
One group means one control plane, simplifying management and reducing public expenditures. Although the control plane is necessary for coordination, its value comes to enable the implementation of the effective work burden rather than running directly business applications.
In addition, many points above are equivalent to improving the cost. With one group, you just need to configure the monitoring (For examplePrometheus), registration tools, and once, which reduces duplication. Automation at sites simplify operations, which helps to manage costs without adding unnecessary infrastructure expenses.
The downsides of the giant mass approach
Unfortunately, the giant mass option is not only the lonely rainbows. There are specific negative aspects.
A radius with a larger explosion
The more the group, the more the difference. Unfortunately, this means that if something bad happens to the group, this chaos will happen to doing more difference. It occurs regardless of whether the interruption of the interruption of the harmful actor, the wrong formation or hunger resources.
When an actually harmful actor violates access, the larger collection is the most terrifying burden of work, and the actor can harm more of them.
Even without harmful actors, every maintenance and upgrade can affect a group on its users; The more the group, the more potential effect. When planning to upgrade one group, you need to perform an effect of influence that includes all users and teams in the institution.
Multiple complex management
Even within one organization, multiple teams will use the kubernetes group. Even if every team member behaves professionally, we must develop strict policies to avoid issues. If the collection is similar to the building, you can still put locks on your apartment even if you have friendly neighbors. Likewise, the bloc official must impose strict rules to make the participation of the bloc acceptable.
At least, we need isolation in the area of strict names to avoid unnecessary access, resource shares and enforcement of fairness through the difference. The problems caused by the use of a single group by teams via one institution over a hundred times if the group is multi -tenant and shared with many organizations.
The limits of expansion
Regardless of the extent of Kubernetes, it is still a physical system with material limits. For example, some objects have a clear limit, but even if you never reach them, approaching them will require excellent system management skills with some settings.
Even so, the more pregnancy you put on the API Kubernetes server, the more slow your system. If you are lucky, it will deteriorate in linear, but there are possibilities to reach some system limit and destroy everything once.
Classes at the mass level
Kubernetes objects are the area of the name space, but two of them are the group of mass. The object in which the mass range can only be one -like across the entire mass. For example, the definition of the dedicated resource is determined.
This means that if a team wants to use V1 from CRD, then each team on the same group is stuck with V1 if they want to use this CRD. Worse than that, if any team wants to upgrade to V2, it must coordinate through all the teams using CRD to synchronize the upgrade.
What is the ideal size, then?
I can describe the positives and negatives of the very beloved collections, but it reflects the opposite of what we have just seen. For example, very granular groups allow each team to work on its copy of CRD without stepping on the fingers of another team. For this reason, I will avoid a psychological repetition.
Most of the articles, if not all, which hold the pros and cons of each end of a spectrum that recommends a meeting approach in the middle: “a couple” from groups to reduce the worst aspects of each extremist approach. Everything is good and good, but none of them, at least nothing you read, specifically tells us the number of “spouses”. Is it a block for every environment, anyOr production, gradual or development? Is it a group for each team?


I will take a risk and announce two groups: one for production and the other for everything else. How can you manage the aforementioned negatives? Read.
Vcluster
VCLUSER is an open source product that allows the creation of so -called virtual groups. VCLUSER is part of the CNCF scene, specifically the distribution of approved kubernetes. Being an approved distribution means that a virtual group offers every Kubernetes applications that you can expect, and you can publish any application on it just like any other group of kubernetes.
VCLUSER works by creating virtual mass in a dedicated name space. You can select the latter, or VCLUSER will conclude from the default block name. By default, it creates a control aircraft using vanilla K8s, but you can choose another group, such as K3s.
Likewise, it stores its composition by default in the SQLite database, which works well for temporary and pre -production groups, such as those that create it to request a withdrawal. Instead, you can rely on regular or even external databases such as MySQL or Postgres as a data store for permanent use, best flexibility and expansion in the default group.

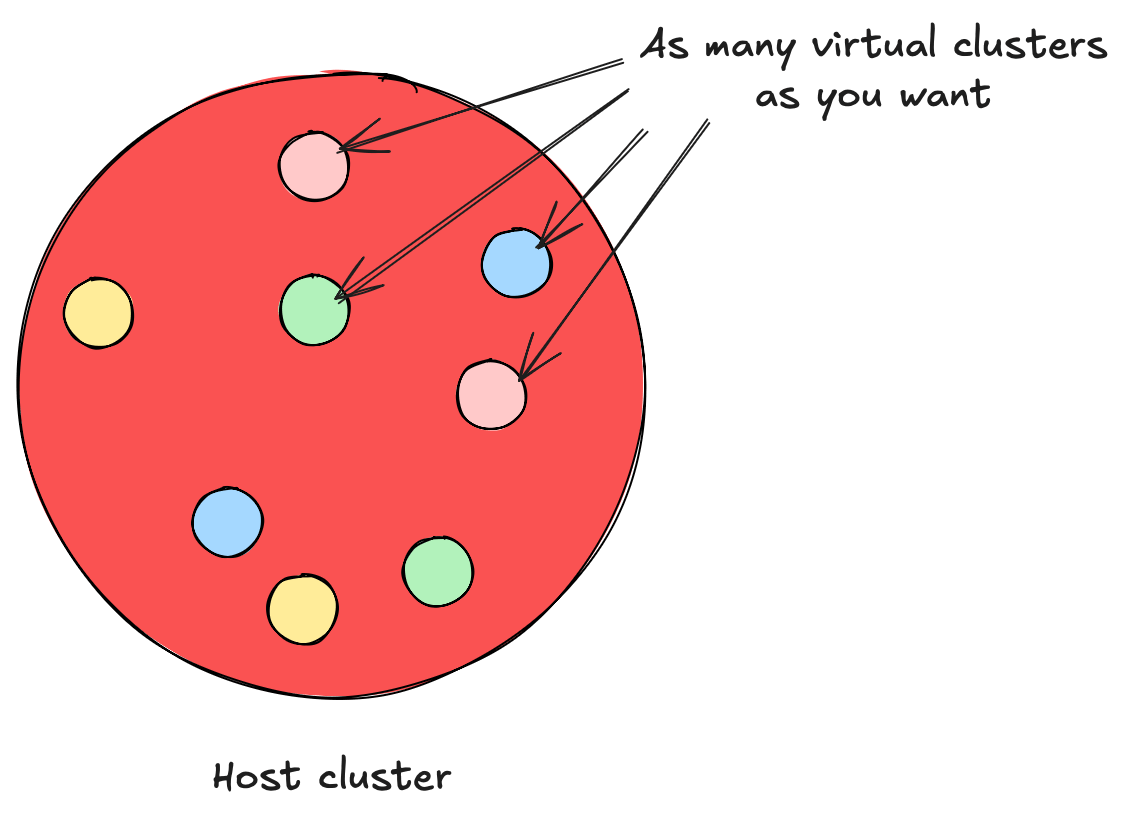
Once you create a virtual collection via Cli or Helm scheme, you can contact it. CLI is created by the customer’s context for allocated kubeconfig. From within a virtual set, users do not see other virtual groups.
If you need to reach the host’s block resources from the virtual mass or vice versa, the VCLUSER uses the so -called synchronization that coincides with the back and forth, according to the formation file. In this way, you can prepare an Ingress console on the host group and select your entry objects in the virtual block.
How to reduce VCLUSter from giant mass downsides
Let’s review each negative side of a giant group and how VCLUSTER is treated.
- The largest diameter of the explosion: When using a virtual block, the diameter of the explosion is automatically contained within its borders. If you want to be conservative, aim to approach small details, such as a group for each team and an environment.
- Multiple tenants: multiple tenants have ended since tenants do not see each other and isolate within their virtual groups.
- The limits of expansion: While the borders are still present, the opportunities for access to them decrease with the number of virtual groups. If your giant group has 100,000 services, it is now spreading in all virtual groups.
- Maintenance promotions and risk: The tasks of promotion and maintenance are limited to one virtual range. You can play it in turn, and it will only affect the virtual groups you target.
- Bloc level objects: Finally, with virtual groups, each team can install its copy of CRD, and connects their CRD. Each team is allowed to be completely independent of each other with regard to the CRD version they use.
But I need different groups!
While one giant group provides convincing advantages, there are contexts in which a multi -range approach is justified. The most common reason is geographical distribution – specific applications require groups in multiple areas to meet compliance requirements, reduce cumin or provide disaster recovery. For example, companies operating under GDP or financial regulations may need strict data accommodation data, which require special groups in the region. Likewise, institutions with strict safety situations may impose full isolation between environments or business units, making separate groups difficult.
However, even in these cases, Vcluster is still relevant. It is allowed to reduce the number of physical groups while enabling the semester of the work burden at a virtual level. Instead of creating a sprawling scene for kubernetes groups, the teams can spread regional virtual groups within one host group, balance isolation and complexity of operation.
conclusion
Copernitz’s decisions are decisive and long -term. While many defenders of the medium -Earth approach between one group and many small factories, they rarely determine the exact preparation. Instead of guessing the number of groups that must be created, unifying everything in one giant group is well managing more logical. Benefits – the use of Better resources, decreased operational general expenses, simplified networks, central governance, and cost efficiency – they turn to negative aspects.
However, the traditional negative aspects of a giant group, such as the radius of the larger explosion, multiple complications, expansion limits, upgrade challenges, and blocks of the mass level, are correct concerns. This is where Vcluster changes the game. Using virtual groups, you can keep all the advantages of one giant group while reducing their worst disadvantages. VCLUSER isolates work burdens, reduces operational risks, falls dynamically, simplifies promotions, removes disputes over things at the level of the mass.
Enhanced with VCLUSER, one production group and one giant group for everything else, is the best approach to long -term expansion, efficiency, and ease of processes.




 cools and heats gold, but this distinctive code of $ 0.025 may save the best in the upward trend now")