
Authors:
(1) Anthi Papadopoulou, Language Technology Group, Oslo University, Gaustadalleen 23B, 0373 Oslo, Norway and the corresponding author ([email protected]);
(2) Pierre Leson, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(3) Mark Anderson, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
4)
(5) Eldiko Pilan, Language Technology Group, Oslo University, Gaustadalleen 23B, 0373 Oslo, Norway.
Links table
Abstract and 1 introduction
2 background
2.1 Definitions
2.2 NLP approach
2.3 Publish privacy retaining data
2.4 Conversion Privacy
3 data sets and 3.1 standards of non -identification of text (tab)
3.2 CVs Wikipedia
4 The entity’s identifier for privacy
4.1 The characteristics of Wikidata
4.2 Silver Corpus and Model Tuning
4.3 Evaluation
4.4 Unlike the poster
4.5 Identity of the semantic type
5 indicators of privacy risk
5.1 LLM Possibilities
5.2 Extension classification
5.3 Disorders
5.4 Signs Sequence and 5.5 Search on the Internet
6 Analysis of the indicators of privacy and 6.1 evaluation measures
6.2 Experimental results and 6.3 discussions
6.4 sets of risk indicators
7 conclusions and future work
advertisements
Reference
Pursuit
A. Human characteristics from Wikidata
for. Entity recognition training parameters
C. The name agreement
Llm: basic models
E. Training and performance volume
Wow thresholds of turmoil
5.2 Extension classification
The approach in the previous section benefits from being a relatively year, as it is only considered the combined LLM and the expected PII. However, it does not take into account the content of the text from the same range. We now provide an indicator that includes this text information to predict whether the text period poses high own risks, and therefore must be hidden.
Tangantly, we are ranging from the previous section by adding to the features of the pre -text representation from a large language model. Consequently, the work is based on a mixture of numerical features (the combined LLM possibilities that have been discussed above, to which we add the number of words and sub -words to bloating), a factional feature (coding of PII type), and a direction of the extent of the text. Decally, the transformer -based language model that results in this voting representation is adjusted to this prediction task.

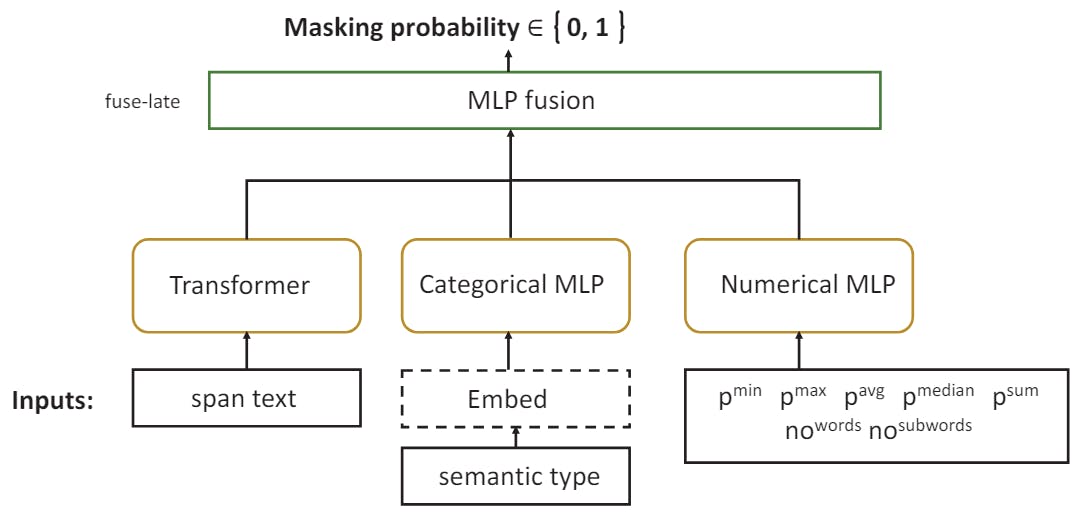
The structure of the resulting model is clarified in Figure 2. Tangier, typical training is carried out using the automatic multimedia rapprochement (SHI ET Al Here we use the Electra Terminator model due to the performance of good coding (Clarak et al Categorical and digital features are treated by standard MLP. After training each model separately, its output (sequence) is assembled by MLP model using an valve strategy near the output layer. Table 4 provides some examples of input.


For our experiments, we are already suitable for the work of the training data collections in the Exposed Wikipedia biography and Tab Corpus.
5.3 Disorders
The former risk indicators use the features extracted from the text period to simulate the decisions of the disguise of human broadcasters. However, they are not able to determine the amount of information that Pii SPAN can contribute to redefining the identity. They also think of every PII period in isolation, which ignores the fact that the semi -matching controversy is specifically the risk of privacy due to combination with each other. We now turn to the privacy risk index seeking to address these two challenges.
This approach is inspired by the ways of convenience (Li et al., 2016; Ding et al One of these methods is IMEN ONE that changes the inputs to the model through modification or removal, and notes how this change affects the predictions in the direction of the estuary (Kindermans et al., 2019; Li et al In our case, we Disturbance Inputs by changing one or more PII stretching and analyzing the consequences of this change on the possibility of another PII’s language model in the text.
Consider the following text:


To assess what extends to the mask, we use a large Roberta model (Liu et al We start by calculating the possibility of the target period with the rest of the context available in the text. Then we hide each other PII period in the document and re -calculate the possibility that the target range is to determine how the absence of the PII period affects the possibility of the target period.
For reasonable estimates, we must hide all the distances indicating the same entity while calculating the possibilities. In example 9, Michael Linder and Linder Refer to the same entity. We use in our experiences the links of the common reference appointed to Tab Corpus and the CV collection Wikipedia.






