
Links table
Abstract and 1. Introduction
-
Blind
2.1 Distinguished symbol analysis
2.2 indicators to discover trained symbols without training and 2.3 checking the candidate codes
-
results
3.1 The effectiveness of indicators and verification
3.2 common notes
3.3 Model notes
-
Closed source models
-
Discussion, recognition and references
A. Verification details
for. Short preliminary on UTF-8 coding
Jim Exit to check API
3 results
In this section, we offer a summary of our main results regarding the disclosure of the distinguished symbol. Looking at the nature of the model and the wide size of the results, we discuss some common results in addition to presenting some representative examples of certain models. Detailed reports cover all models that have been tested and the distinctive code types are available in our warehouse.
3.1 The effectiveness of indicators and verification
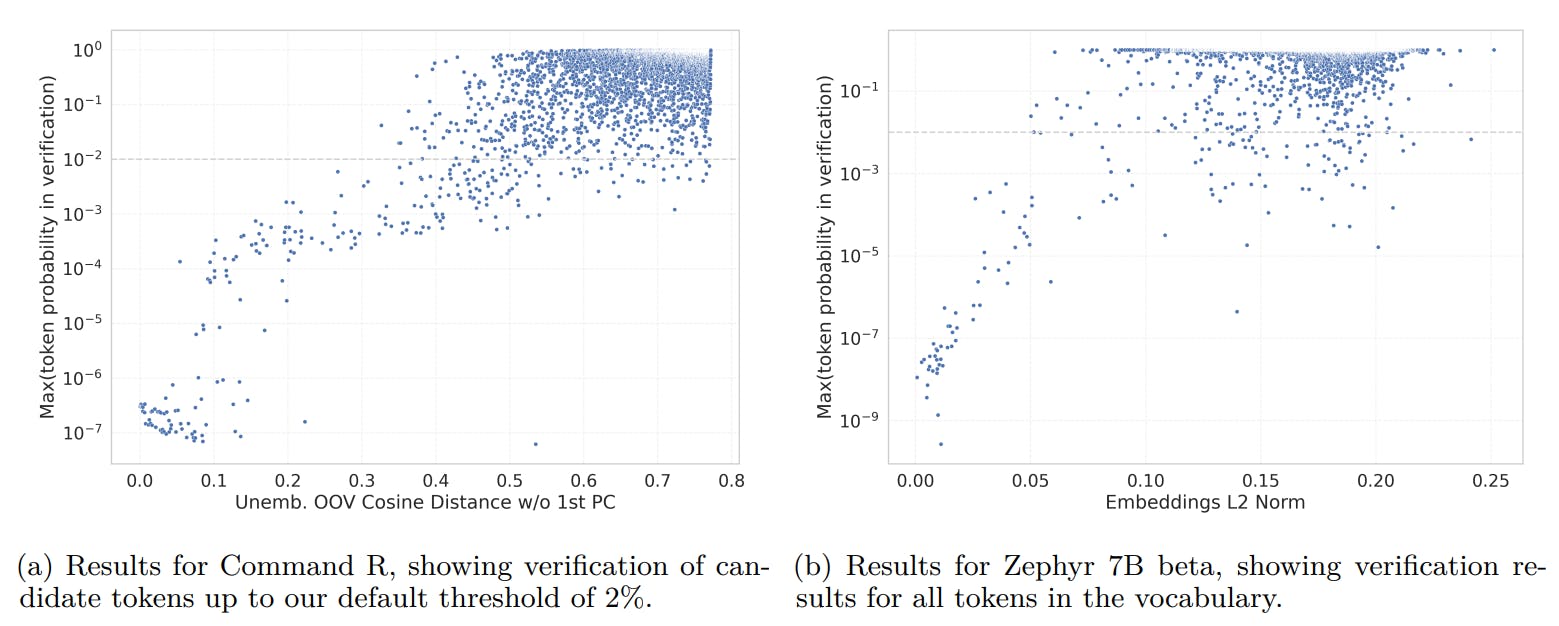
Figure 1 shows that despite its relative simplicity, our indicators are very predictable to the maximum possibility of symbolic prediction. To measure the number of symbols discovered in verification compared to the selection of our candidates, we applied the move to check all the icons of the Zephyr-Beta model [12]. This resulted in 137 out of 31,747 symbols verified compared to 76 out of 637 when tested only 2 %.
Second, although the training data statistics are rarely available, we have been able to verify that our distinguished symbol indicators are closely related to the frequency codes that appear in the training data of the Olmo v1.7 model [13]. Figure 2 shows a strong connection to all proposed indicators, not only the prediction trained symbols, but extend to the full range of symbolic frequencies.
Finally, Figure 3 shows additional examples of indicators, which indicates clear peaks in the graph near zero, and the high relationship between alternative indicators in this region.

There are some cases where the indicators we use are more predictive to the distinctive symbol to urge unwanted output compared to our claim techniques. With regard to verification, there are some cases in which the indicators that we use are provided with a more reliable indication of the tendency of the distinctive symbol to urge unwanted output in the model claim compared to the techniques of demanding verification. These cases include lack of consistency of input/output, as symbols are found only as inputs (for example,
Table 1 displays verification statistics and an example of the distinctive symbols of the evaluation models. The number of distinctive symbols that have been verified significantly vary through different model families and the size of the distinctive symbol vocabulary, as well as depending on the number of unused special symbols that the distinctive symbol is allowed as the introduction of a normal text. The percentage of censored symbols usually ranges between 5-50 % of the tested candidate symbols, which correspond to 0.1-1 % of the total vocabulary.


")

