
Links table
Abstract and 1 introduction
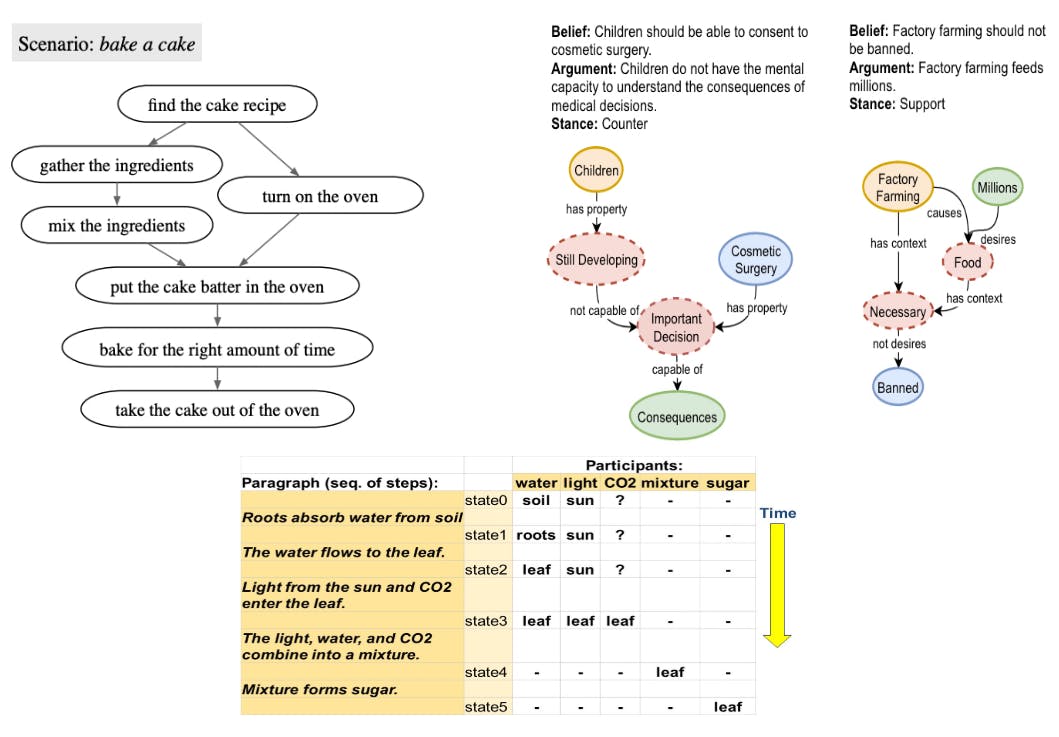
2 Cocogen: Representing coordinated structures with code and 2.1 conversion (T, G) to the Bethon icon
2.2 Few rounds pay to generate G.
3 evaluation and 3.1 experimental preparation
3.2 Screen generation: Proscripe
3.3 Entity Case Tracking: Propara
3.4 Media graph
4 analysis
5 relevant work
6 Conclusion, declarations, restrictions, and references
Few estimates of models size
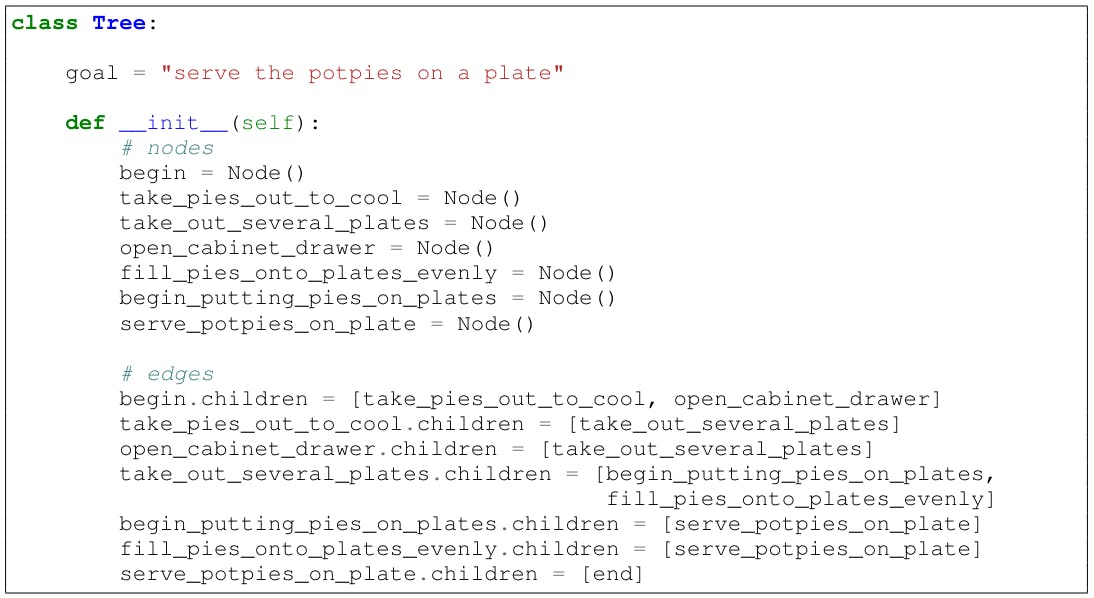
B Create a dynamic mentor
C human evaluation
D data collection statistics
Sample outputs
Development and
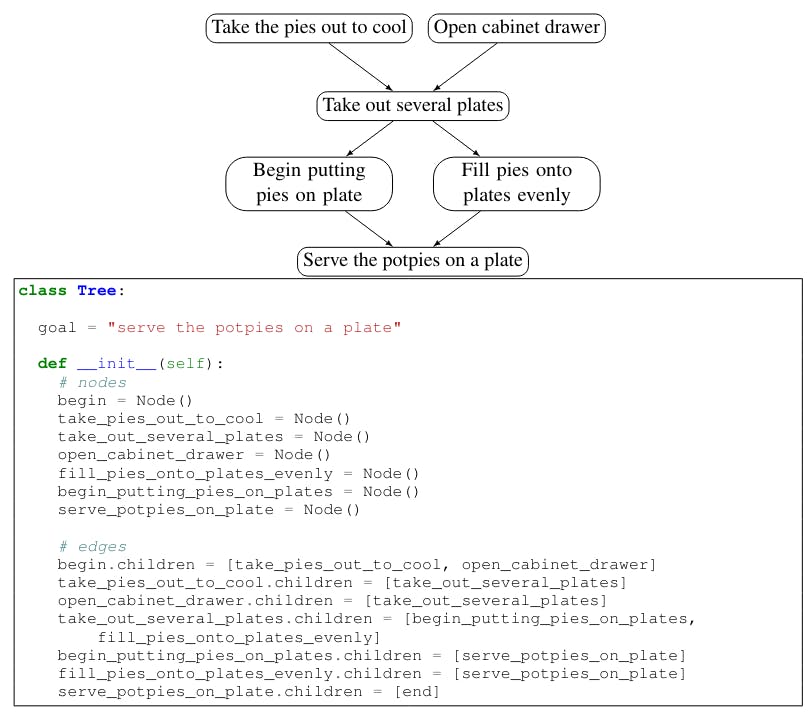
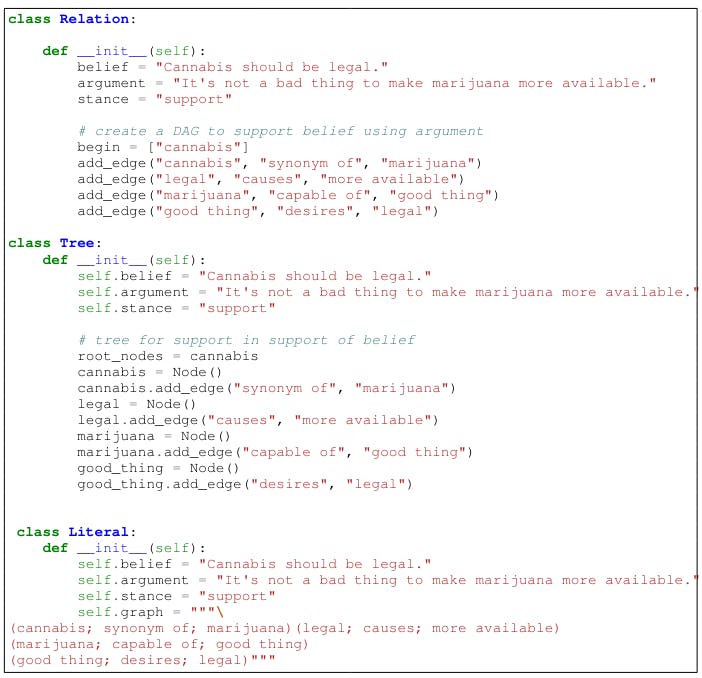
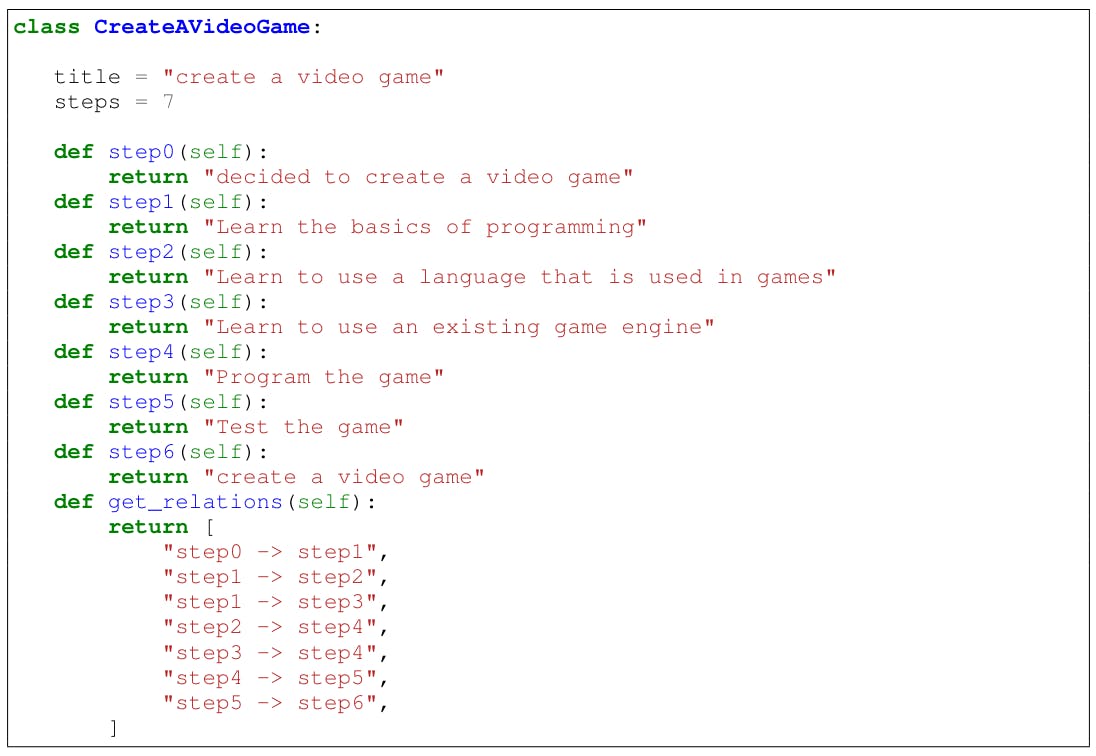
G the Python class design for an organized mission
H the effect of the size of the model
I am the difference in claims
G the Python class design for an organized mission
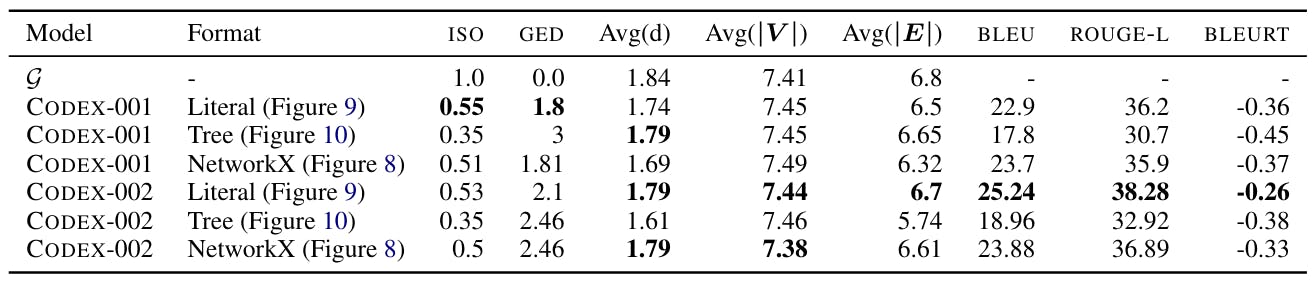
Figure 7 shows three different designs for exploration. For ProscRIPT, various formats include PROSCRIPT as Networkx[8] Category (8), a group -like category 9, and as a tree (10).
H the effect of the size of the model
The Openai Codex model is available in two versions[9]Code-Davinci -001 and Code-Davinci-002. Although the exact sizes of models are unknown due to their royal nature, the API Openai states that Code-Davinci -002 is the most codex 16 and ?? Cocogen +Code-Davinci -001 compares with Cocogen +Code-Davinci -002. Note that both Code-Davinci -001 and Code-Davinci -002 can fit 4000 icons, so the number of context examples was identical to the two preparations. The results show that for identical demands, Cocogen +Code-Davinci -002 is greatly outperforming Cocogen +Code-Davinci -001, indicating the importance of a better model to generate code.




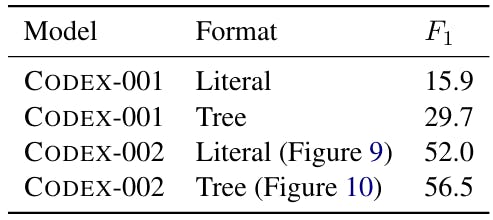
The volume of the form v against the sensitivity to claim Table 14 shows the performance of the Codex -001 (smaller) and Codex -002 (larger, see also Appendix A) on identical claims. Our experiences show that with the increase in the size of the model, the form of the model in fast design may become gradually easier.
I am the difference in claims
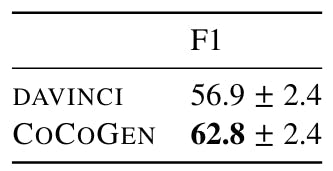
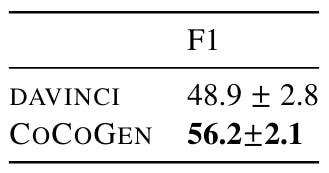
We run each experience with 4 different random seeds, where random seeds decide to arrange examples in the claim. We find the minimum contrast between operations using different fixed claims between 3 runs. Moreover, as shown in Table, 19, 20, 20 and 21, all cocogenic improvements on Da Vinci are statistically (the value of P <0.001).


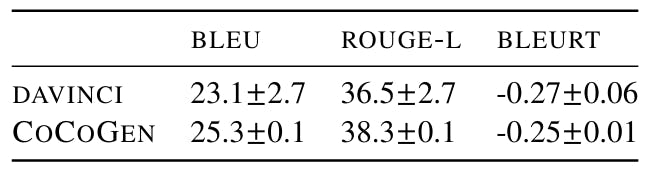












[9] As of June 2022
Authors:
(1) Aman Madan, Language Technology Institute, University of Carnegie Mellon, United States of America ([email protected]);
(2) Shuian Chu, Institute of Language Technologies, University of Carnegie Mellon, USA)[email protected]);
(3) URI Alon, Institute of Language Technologies, University of Carnegie Mellon, USA)[email protected]);
(4) Yang Yang, Institute of Language Technologies, University of Carnegie Mellon, USA)[email protected]);
(5) Graham Newbig, Institute of Language Technologies, University of Carnegie Mellon, USA)[email protected]).




